Semantic Segmentation¶
paddlex.seg.DeepLabv3p¶
paddlex.seg.DeepLabv3p(num_classes=2, backbone='MobileNetV2_x1.0', output_stride=16, aspp_with_sep_conv=True, decoder_use_sep_conv=True, encoder_with_aspp=True, enable_decoder=True, use_bce_loss=False, use_dice_loss=False, class_weight=None, ignore_index=255, pooling_crop_size=None, input_channel=3)
构建DeepLabv3p分割器。
参数
- num_classes (int): 类别数。
- backbone (str): DeepLabv3+的backbone网络,实现特征图的计算,取值范围为[’Xception65’, ‘Xception41’, ‘MobileNetV2_x0.25’, ‘MobileNetV2_x0.5’, ‘MobileNetV2_x1.0’, ‘MobileNetV2_x1.5’, ‘MobileNetV2_x2.0’, ‘MobileNetV3_large_x1_0_ssld’],默认值为’MobileNetV2_x1.0’。
- output_stride (int): backbone 输出特征图相对于输入的下采样倍数,一般取值为8或16。默认16。
- aspp_with_sep_conv (bool): aspp模块是否采用separable convolutions。默认True。
- decoder_use_sep_conv (bool): decoder模块是否采用separable convolutions。默认True。
- encoder_with_aspp (bool): 是否在encoder阶段采用aspp模块。默认True。
- enable_decoder (bool): 是否使用decoder模块。默认True。
- use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。默认False。
- use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用,当
use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。默认False。- class_weight (list/str): 交叉熵损失函数各类损失的权重。当
class_weight为list的时候,长度应为num_classes。当class_weight为str时, weight.lower()应为’dynamic’,这时会根据每一轮各类像素的比重自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,即平时使用的交叉熵损失函数。- ignore_index (int): label上忽略的值,label为
ignore_index的像素不参与损失函数的计算。默认255。- pooling_crop_size (int):当backbone为
MobileNetV3_large_x1_0_ssld时,需设置为训练过程中模型输入大小,格式为[W, H]。例如模型输入大小为[512, 512], 则pooling_crop_size应该设置为[512, 512]。在encoder模块中获取图像平均值时被用到,若为None,则直接求平均值;若为模型输入大小,则使用avg_pool算子得到平均值。默认值None。- input_channel (int): 输入图像通道数。默认值3。
train¶
train(self, num_epochs, train_dataset, train_batch_size=2, eval_dataset=None, eval_batch_size=1, save_interval_epochs=1, log_interval_steps=2, save_dir='output', pretrain_weights='IMAGENET', optimizer=None, learning_rate=0.01, lr_decay_power=0.9, use_vdl=False, sensitivities_file=None, eval_metric_loss=0.05, early_stop=False, early_stop_patience=5, resume_checkpoint=None):
DeepLabv3p模型的训练接口,函数内置了polynomial学习率衰减策略和momentum优化器。
参数
- num_epochs (int): 训练迭代轮数。
- train_dataset (paddlex.datasets): 训练数据读取器。
- train_batch_size (int): 训练数据batch大小。同时作为验证数据batch大小。默认2。
- eval_dataset (paddlex.datasets): 评估数据读取器。
- save_interval_epochs (int): 模型保存间隔(单位:迭代轮数)。默认为1。
- log_interval_steps (int): 训练日志输出间隔(单位:迭代次数)。默认为2。
- save_dir (str): 模型保存路径。默认’output’
- pretrain_weights (str): 若指定为路径时,则加载路径下预训练模型;若为字符串’IMAGENET’,则自动下载在ImageNet图片数据上预训练的模型权重;若为字符串’COCO’,则自动下载在COCO数据集上预训练的模型权重(注意:暂未提供Xception41、MobileNetV2_x0.25、MobileNetV2_x0.5、MobileNetV2_x1.5、MobileNetV2_x2.0的COCO预训练模型);若为字符串’CITYSCAPES’,则自动下载在CITYSCAPES数据集上预训练的模型权重(注意:暂未提供Xception41、MobileNetV2_x0.25、MobileNetV2_x0.5、MobileNetV2_x1.5、MobileNetV2_x2.0的CITYSCAPES预训练模型);若为None,则不使用预训练模型。默认’IMAGENET’。
- optimizer (paddle.fluid.optimizer): 优化器。当该参数为None时,使用默认的优化器:使用fluid.optimizer.Momentum优化方法,polynomial的学习率衰减策略。
- learning_rate (float): 默认优化器的初始学习率。默认0.01。
- lr_decay_power (float): 默认优化器学习率衰减指数。默认0.9。
- use_vdl (bool): 是否使用VisualDL进行可视化。默认False。
- sensitivities_file (str): 若指定为路径时,则加载路径下敏感度信息进行裁剪;若为字符串’DEFAULT’,则自动下载在Cityscapes图片数据上获得的敏感度信息进行裁剪;若为None,则不进行裁剪。默认为None。
- eval_metric_loss (float): 可容忍的精度损失。默认为0.05。
- early_stop (bool): 是否使用提前终止训练策略。默认值为False。
- early_stop_patience (int): 当使用提前终止训练策略时,如果验证集精度在
early_stop_patience个epoch内连续下降或持平,则终止训练。默认值为5。- resume_checkpoint (str): 恢复训练时指定上次训练保存的模型路径。若为None,则不会恢复训练。默认值为None。
evaluate¶
evaluate(self, eval_dataset, batch_size=1, epoch_id=None, return_details=False):
DeepLabv3p模型评估接口。
参数
- eval_dataset (paddlex.datasets): 评估数据读取器。
- batch_size (int): 评估时的batch大小。默认1。
- epoch_id (int): 当前评估模型所在的训练轮数。
- return_details (bool): 是否返回详细信息。默认False。
返回值
- dict: 当
return_details为False时,返回dict。包含关键字:’miou’、’category_iou’、’macc’、 ‘category_acc’和’kappa’,分别表示平均IoU、各类别IoU、平均准确率、各类别准确率和kappa系数。- tuple (metrics, eval_details):当
return_details为True时,增加返回dict (eval_details), 包含关键字:’confusion_matrix’,表示评估的混淆矩阵。
predict¶
predict(self, img_file, transforms=None):
DeepLabv3p模型预测接口。需要注意的是,只有在训练过程中定义了eval_dataset,模型在保存时才会将预测时的图像处理流程保存在DeepLabv3p.test_transforms和DeepLabv3p.eval_transforms中。如未在训练时定义eval_dataset,那在调用预测predict接口时,用户需要再重新定义test_transforms传入给predict接口。
参数
- img_file (str|np.ndarray): 预测图像路径或numpy数组(HWC排列,BGR格式)。
- transforms (paddlex.seg.transforms): 数据预处理操作。
返回值
- dict: 包含关键字’label_map’和’score_map’, ‘label_map’存储预测结果灰度图,像素值表示对应的类别,’score_map’存储各类别的概率,shape=(h, w, num_classes)。
batch_predict¶
batch_predict(self, img_file_list, transforms=None):
DeepLabv3p模型批量预测接口。需要注意的是,只有在训练过程中定义了eval_dataset,模型在保存时才会将预测时的图像处理流程保存在DeepLabv3p.test_transforms和DeepLabv3p.eval_transforms中。如未在训练时定义eval_dataset,那在调用预测batch_predict接口时,用户需要再重新定义test_transforms传入给batch_predict接口。
参数
- img_file_list (list|tuple): 对列表(或元组)中的图像同时进行预测,列表中的元素可以是预测图像路径或numpy数组(HWC排列,BGR格式)。
- transforms (paddlex.seg.transforms): 数据预处理操作。
返回值
- dict: 每个元素都为列表,表示各图像的预测结果。各图像的预测结果用字典表示,包含关键字’label_map’和’score_map’, ‘label_map’存储预测结果灰度图,像素值表示对应的类别,’score_map’存储各类别的概率,shape=(h, w, num_classes)。
overlap_tile_predict¶
overlap_tile_predict(self, img_file, tile_size=[512, 512], pad_size=[64, 64], batch_size=32, transforms=None)
DeepLabv3p模型的滑动预测接口, 支持有重叠和无重叠两种方式。
无重叠的滑动窗口预测:在输入图片上以固定大小的窗口滑动,分别对每个窗口下的图像进行预测,最后将各窗口的预测结果拼接成输入图片的预测结果。使用时需要把参数pad_size设置为[0, 0]。
有重叠的滑动窗口预测:在Unet论文中,作者提出一种有重叠的滑动窗口预测策略(Overlap-tile strategy)来消除拼接处的裂痕感。对各滑动窗口预测时,会向四周扩展一定的面积,对扩展后的窗口进行预测,例如下图中的蓝色部分区域,到拼接时只取各窗口中间部分的预测结果,例如下图中的黄色部分区域。位于输入图像边缘处的窗口,其扩展面积下的像素则通过将边缘部分像素镜像填补得到。
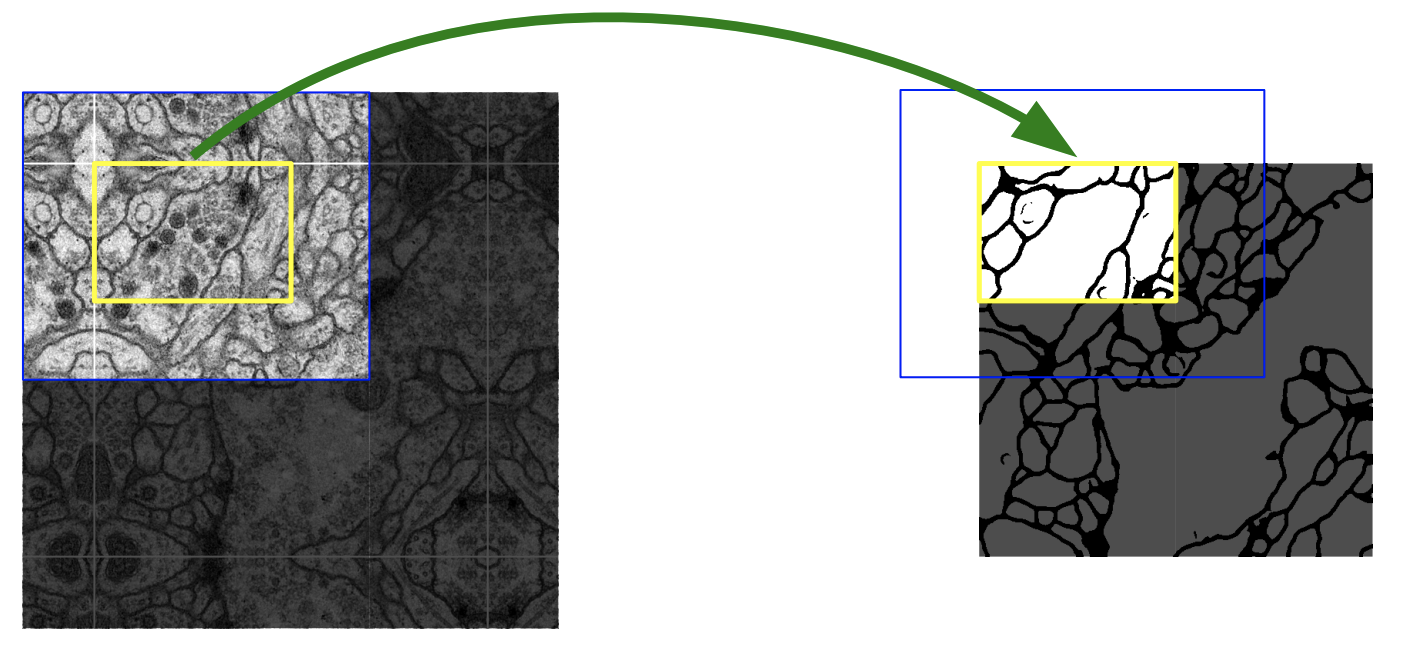
需要注意的是,只有在训练过程中定义了eval_dataset,模型在保存时才会将预测时的图像处理流程保存在DeepLabv3p.test_transforms和DeepLabv3p.eval_transforms中。如未在训练时定义eval_dataset,那在调用预测overlap_tile_predict接口时,用户需要再重新定义test_transforms传入给overlap_tile_predict接口。
参数
- img_file (str|np.ndarray): 预测图像路径或numpy数组(HWC排列,BGR格式)。
- tile_size (list|tuple): 滑动窗口的大小,该区域内用于拼接预测结果,格式为(W,H)。默认值为[512, 512]。
- pad_size (list|tuple): 滑动窗口向四周扩展的大小,扩展区域内不用于拼接预测结果,格式为(W,H)。默认值为[64, 64]。
- batch_size (int):对窗口进行批量预测时的批量大小。默认值为32。
- transforms (paddlex.seg.transforms): 数据预处理操作。
返回值
- dict: 包含关键字’label_map’和’score_map’, ‘label_map’存储预测结果灰度图,像素值表示对应的类别,’score_map’存储各类别的概率,shape=(h, w, num_classes)。
paddlex.seg.UNet¶
paddlex.seg.UNet(num_classes=2, upsample_mode='bilinear', use_bce_loss=False, use_dice_loss=False, class_weight=None, ignore_index=255, input_channel=3)
构建UNet分割器。
参数
- num_classes (int): 类别数。
- upsample_mode (str): UNet decode时采用的上采样方式,取值为’bilinear’时利用双线行差值进行上菜样,当输入其他选项时则利用反卷积进行上菜样,默认为’bilinear’。
- use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。默认False。
- use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。默认False。
- class_weight (list/str): 交叉熵损失函数各类损失的权重。当
class_weight为list的时候,长度应为num_classes。当class_weight为str时, weight.lower()应为’dynamic’,这时会根据每一轮各类像素的比重自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,即平时使用的交叉熵损失函数。- ignore_index (int): label上忽略的值,label为
ignore_index的像素不参与损失函数的计算。默认255。- input_channel (int): 输入图像通道数。默认值3。
- train 训练接口说明同 DeepLabv3p模型train接口
- evaluate 评估接口说明同 DeepLabv3p模型evaluate接口
- predict 预测接口说明同 DeepLabv3p模型predict接口
- batch_predict 批量预测接口说明同 DeepLabv3p模型predict接口
- overlap_tile_predict 滑动窗口预测接口同 DeepLabv3p模型poverlap_tile_predict接口
paddlex.seg.HRNet¶
paddlex.seg.HRNet(num_classes=2, width=18, use_bce_loss=False, use_dice_loss=False, class_weight=None, ignore_index=255, input_channel=3)
构建HRNet分割器。
参数
- num_classes (int): 类别数。
- width (int|str): 高分辨率分支中特征层的通道数量。默认值为18。可选择取值为[18, 30, 32, 40, 44, 48, 60, 64, ‘18_small_v1’]。’18_small_v1’是18的轻量级版本。
- use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。默认False。
- use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。默认False。
- class_weight (list|str): 交叉熵损失函数各类损失的权重。当
class_weight为list的时候,长度应为num_classes。当class_weight为str时, weight.lower()应为’dynamic’,这时会根据每一轮各类像素的比重自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,即平时使用的交叉熵损失函数。- ignore_index (int): label上忽略的值,label为
ignore_index的像素不参与损失函数的计算。默认255。- input_channel (int): 输入图像通道数。默认值3。
- train 训练接口说明同 DeepLabv3p模型train接口
- evaluate 评估接口说明同 DeepLabv3p模型evaluate接口
- predict 预测接口说明同 DeepLabv3p模型predict接口
- batch_predict 批量预测接口说明同 DeepLabv3p模型predict接口
- overlap_tile_predict 滑动窗预测接口同 DeepLabv3p模型poverlap_tile_predict接口
paddlex.seg.FastSCNN¶
paddlex.seg.FastSCNN(num_classes=2, use_bce_loss=False, use_dice_loss=False, class_weight=None, ignore_index=255, multi_loss_weight=[1.0], input_channel=3)
构建FastSCNN分割器。
参数
- num_classes (int): 类别数。
- use_bce_loss (bool): 是否使用bce loss作为网络的损失函数,只能用于两类分割。可与dice loss同时使用。默认False。
- use_dice_loss (bool): 是否使用dice loss作为网络的损失函数,只能用于两类分割,可与bce loss同时使用。当use_bce_loss和use_dice_loss都为False时,使用交叉熵损失函数。默认False。
- class_weight (list/str): 交叉熵损失函数各类损失的权重。当
class_weight为list的时候,长度应为num_classes。当class_weight为str时, weight.lower()应为’dynamic’,这时会根据每一轮各类像素的比重自行计算相应的权重,每一类的权重为:每类的比例 * num_classes。class_weight取默认值None是,各类的权重1,即平时使用的交叉熵损失函数。- ignore_index (int): label上忽略的值,label为
ignore_index的像素不参与损失函数的计算。默认255。- multi_loss_weight (list): 多分支上的loss权重。默认计算一个分支上的loss,即默认值为[1.0]。也支持计算两个分支或三个分支上的loss,权重按[fusion_branch_weight, higher_branch_weight, lower_branch_weight]排列,fusion_branch_weight为空间细节分支和全局上下文分支融合后的分支上的loss权重,higher_branch_weight为空间细节分支上的loss权重,lower_branch_weight为全局上下文分支上的loss权重,若higher_branch_weight和lower_branch_weight未设置则不会计算这两个分支上的loss。
- input_channel (int): 输入图像通道数。默认值3。
- train 训练接口说明同 DeepLabv3p模型train接口
- evaluate 评估接口说明同 DeepLabv3p模型evaluate接口
- predict 预测接口说明同 DeepLabv3p模型predict接口
- batch_predict 批量预测接口说明同 DeepLabv3p模型predict接口
- overlap_tile_predict 滑动窗预测接口同 DeepLabv3p模型poverlap_tile_predict接口